数据清洗
什么是数据清洗
数据清洗是面向post-pretrain场景下预训练泛文本数据的一站式数据处理方案,通过对数据进行异常清洗、文本过滤、文本去重和去除隐私信息,大幅提升数据质量,优化模型训练效果。
面向post-pretrain场景的数据清洗
登录到千帆大模型操作台,在左侧功能列数据处理中选择数据清洗,进入数据清洗的主任务界面,整体流程如下:

1.选择数据集
在数据处理-数据清洗页面中,选择“创建任务”。

- 处理前数据集:存放被清洗的泛文本源数据。
- 处理后数据集:存放清洗后的数据。
2.异常清洗
完成上一步的操作后,在功能列左侧选择异常清洗配置开关,效果展示区展示内置数据在指定清洗操作下的效果预览。

可选异常清洗配置如下所示:
1)移除不可见字符:移除ASCII中的一些不可见字符, 如0-32 和127-160这两个范围。 等。 完成上一步的操作后,在功能列左侧选择过滤配置开关,效果展示区展示内置数据在指定清洗操作下的效果预览。 可选过滤配置如下所示,每项过滤配置都可在打开后进行范围内取值: 1)检查文档的词数目:词数目不在指定范围会被过滤掉,如中文,取值范围[1,1000000](正整数)。 完成上一步的操作后,在功能列左侧选择去重配置开关,效果展示区展示内置数据在指定清洗操作下的效果预览。 可选去重配置为simhash-operator,根据海明距离计算文档相似度, 相似度<=海明距离,认为两个文档相似。(范围:4-6)。 完成上一步的操作后,在功能列左侧选择去隐私配置开关,效果展示区展示内置数据在指定清洗操作下的效果预览。 可选去隐私配置如下所示: 1)去除数字:去除数字和字母数字标识符,如电话号码、信用卡号、十六进制散列等,同时跳过年份和简单数字的实例。 完成上述步骤后,选择“提交”按钮,提交清洗任务。 任务提交后,您可至“清洗任务管理”页面,查看基本信息和任务详情。 对于清洗失败的任务,您可以“重新启动”,再次拉起数据清洗操作,对于“进行中”的清洗任务,只有查看详情和终止任务操作,不可删除。
2)规范化空格:将不同的unicode空格比如 u2008,转成正常的空格。
3)去除乱码:去除乱码和无意义的unicode。
4)繁体转简体:将文档中的繁体字转换成简体。
5)去除网页标识符:移除文档中的html标签,如,
6)去除表情符:去除表情符如
3.过滤
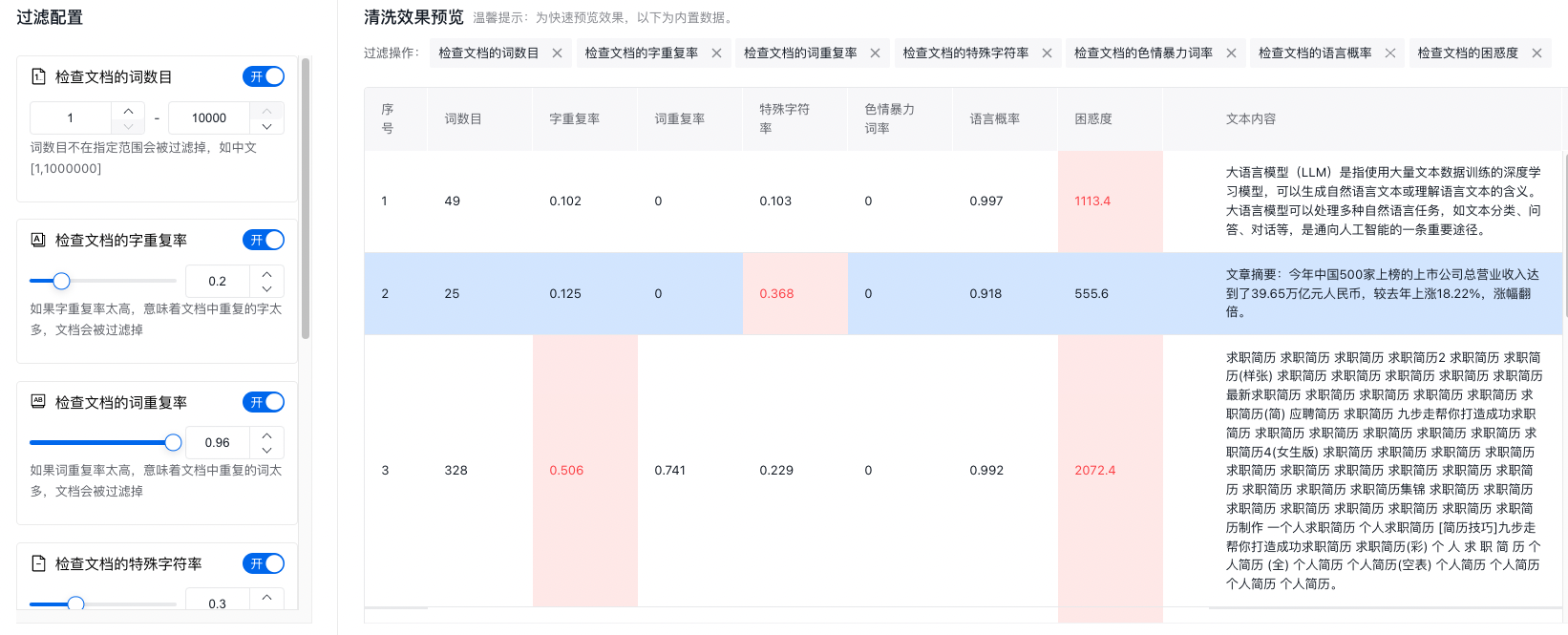
2)检查文档的字重复率:如果字重复率太高,意味着文档中重复的字太多,文档会被过滤掉,取值范围[0,1]。
3)检查文档的词重复率:如果词重复率太高,意味着文档中重复的词太多,文档会被过滤掉,取值范围[0,1]。
4)检查文档的特殊字符率:如果特殊字符率太高,意味着文档中特殊字符太多,文档会被过滤掉,取值范围[0,1]。
5)检查文档的色情暴力词率:如果色情暴力词率太高,文档会被过滤掉,取值范围[0,1]。
6)检查文档的语言概率:如果语言概率太低,文档会被过滤掉,取值范围[0,1]。
7)检查文档的困惑度:如果困惑度太高,文档会被过滤掉,取值范围[0,5000]。4.去重

5.去隐私
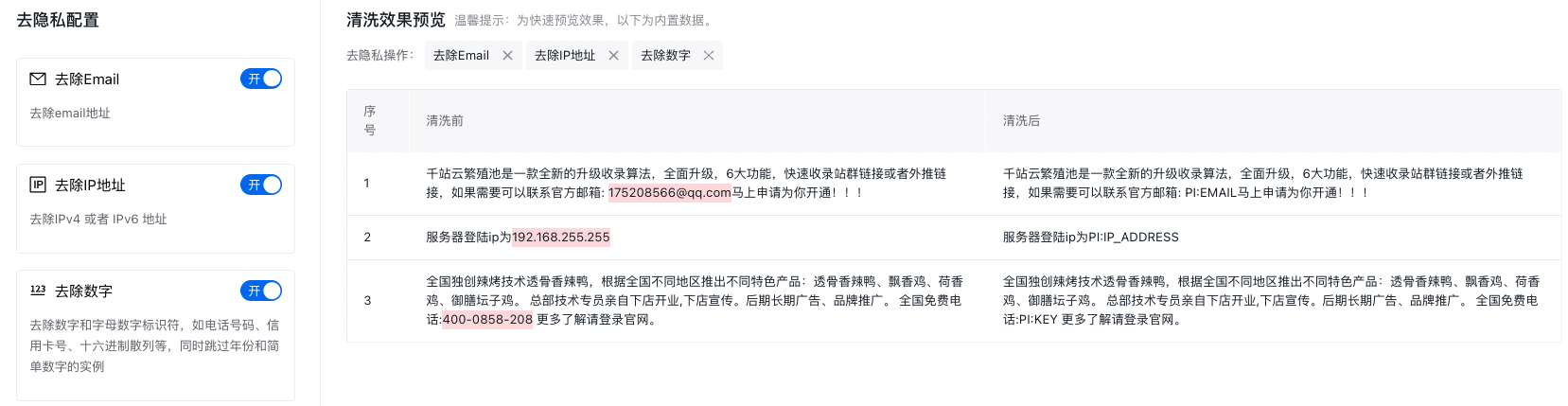
2)去除Email:去除Email地址。
3)去除IP地址:去除IPv4 或者 IPv6 地址。查看数据清洗任务
