创建我的模型
用户模型简介
“我的模型”纳管了用户训练、压缩生成的大模型或导入的第三方HF(HuggingFace)格式模型。
一个用户模型可以包含多个版本,可以从版本维度对模型进行评估、压缩和部署等操作。
平台训练的模型可以通过“模型发布”或“创建模型”,在“我的模型”下进行纳管,而压缩生成的模型则是在压缩完成后直接发布。
以下是平台训练模型创建的步骤:
模型创建步骤
登录到千帆大模型操作台,在左侧功能列模型管理中选择我的模型,进入创建模型的主任务界面。
- 点击“创建模型”按钮,进行模型新建;
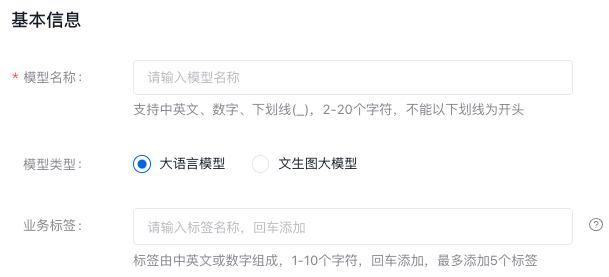
- 填写模型的基本信息,包括以下内容:
- 模型名称:自定义的模型名称,支持中文、英文、数字、下划线(_),2-20个字符以内,不能以下划线为开头。
- 模型类型:平台支持大语言模型或文生图大模型。
- 业务标签:非必填,您可通过业务标签来标记模型适用的业务范围,模型列表页支持对业务标签的模糊搜索。
- 选择已完成的训练任务及运行或直接导入第三方模型,创建一个新的模型版本,具体字段包括:
- 模型版本:平台自动生成,版本号从V1起递增。
- 模型版本描述:非必填项,自定义的版本描述,记录模型的业务场景、使用方式等信息。
- 模型来源分为大模型训练任务和对象存储BOS(文生图大模型不支持对象存储BOS导入)。

选择模型来源为大模型训练任务
- 模型训练方式:必选项,可选大模型调优或RLHF-强化学习训练方式,相关内容参考SFT使用说明及强化学习使用说明。
- 训练任务:必选项,选择相应模型训练方式的训练任务。
- 运行名称:必选项,选择相应训练任务中已完成的运行的名称。
选择模型来源为对象存储BOS
当您选择模型类型为文生图大模型时,不支持对象存储BOS导入。
需要您提前开通对象存储BOS服务,快速上手模型导入流程,可参考快速导入并部署第三方模型文档说明。
- Bucket:选择对象存储BOS中模型所属的Bucket。
- 文件夹:请选择模型所在的⽂件夹,⽬录内最多不能超过1000个⽂件,否则可能导⼊失败。关于文件上传的详细操作可参考相关指导。
- 模型格式:默认为HuggingFace > Transformers,其目录架构如下
模型目录/
├── config.json
├── tokenizer_config.json
├── pytorch_model.bin
├── .......
- 输入输出格式:
- 续写模式:适用Pretrain或Post-Pretrain Base模型。
- 对话模式:对话模式适用经过指令精调的Chat模型:平台将根据以下配置自动拼接当前用户问题和历史轮次问答,方便用户在线测试或接入对话类应用。
1)当前问题拼接规范:按此处规范自动将当前用户问题拼接至Prompt中;{question}变量对应用户最新一轮问题。为尽可能保证模型效果,此处拼接规范应与模型精调时的问答拼接方式一致。
2)历史问答拼接规范:按此处规范自动将历史轮次问答拼接至Prompt中;{question}, {answer}变量分别对应历史用户问题和模型回答。为尽可能保证模型效果,此处拼接规范应与模型精调时的问答拼接方式一致。
3)外层Prompt模板:大模型指令精调时使用的Prompt模板,在模型调用时自动应用。
- 高级配置:默认关闭。大模型部署时的高级配置项,对模型推理性能和效果有一定影响,其默认示例如下:
{
"load_model_class": "AutoModelForCausalLM",
"load_tokenizer_class": "AutoTokenizer",
"enable_auto_batch": true,
"custom_end_str": "",
"token_decode_return_blank": true,
"tokenizer_special_tokens": {}
}
当您选择【对话模式】后,相关的高级配置可参考快速导入第三方模型相关内容。
信息填写完成后,点击“确定”,即创建一个新的模型(及版本);后续可在列表页或模型详情页新增模型版本。
最后修改时间: 1 年前