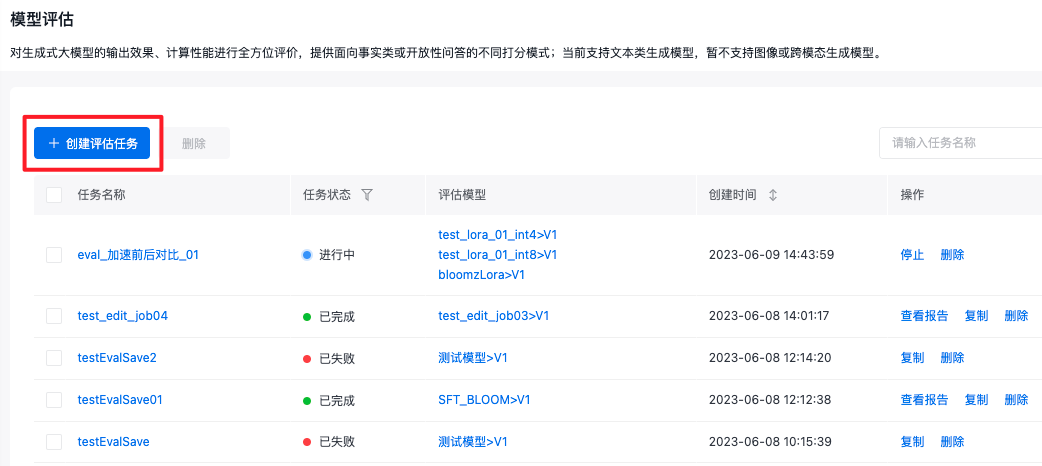
创建模型评估任务
什么是评估数据集
在人工智能模型开发过程中,通常是将数据集划分为训练集、验证集和测试集三个部分。其中,训练集用来训练模型,验证集则用于调整模型的超参数和选择合适的模型,而测试集则是在模型训练完成后,用于最终评估模型的性能,这就是评估数据集(即测试集)。
评估数据集通常是在与训练数据集相似的情况下收集的,因此可以用来代表真实世界的样本数据。通过对评估数据集的评估,可以了解模型在不同场景下的表现,从而更好地优化模型。同时,评估数据集还可以用来验证模型的泛化能力,即模型在未见过的数据上的表现如何。
创建模型评估任务
登录到千帆大模型操作台,在左侧功能列选择模型评估,进入模型评估主任务界面。
点击“创建评估任务”按钮,进入新建评估任务页面。(若没有该按钮,请查看任务计费说明)
由用户填写评估任务所需的基本信息、评估配置、资源配置。
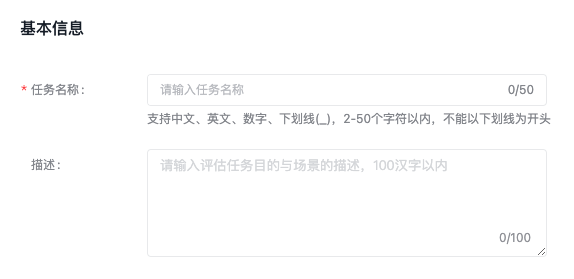
基本信息
填写评估任务名称、评估任务描述.
评估配置
待评估模型: 支持选择多个模型版本同时评估,最多选择5个。支持同时选择预置模型和用户训练模型,具体支持范围详见模型评估支持范围 。
评估数据集: 支持选择平台数据集或预置数据集作为评估数据集,支持选择文本对话(有排序、非排序)类型的数据。数据集中的标注样本数量需大于3,否则将无法发起评估任务,如您选择裁判员模型打分,则需要您上传的样本全部完成标注。
每次评估数据集标注样本数不可超过10000条。若数据集保存在BOS中,请勿在提交任务后修改BOS数据。修改后可能会导致任务失败!
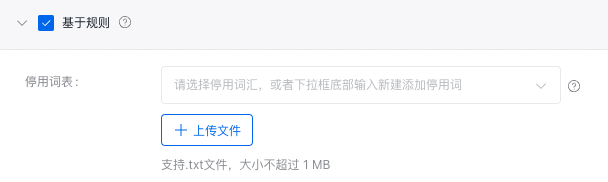
基于规则
使用预置的相似度或准确率打分规则对比模型生成结果与真实标注的差异,从而计算模型指标。
为避免特殊字符及单词对模型效果评估的影响,可设置停用词表,评估时将自动过滤。下载停用词表示例(以空格或回车分隔不同停用词)。
基于裁判员模型
使用能力更强的大模型作为裁判员,对被评估模型的生成结果进行自动化打分,适用于开放性或复杂问答场景。
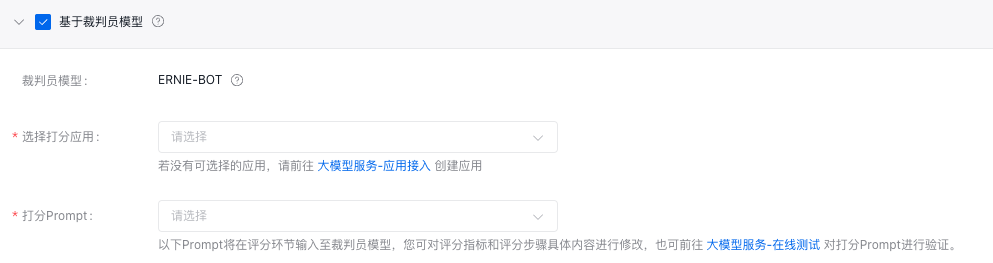
- 裁判员模型:默认裁判员为ERNIE-Bot,百度⾃⾏研发的旗舰级⼤语⾔模型,覆盖海量中⽂数据,具有更强的对话问答、内容创作⽣成等能⼒;⽀持作为裁判员⼤模型打分。
- 选择打分应用:选择您创建的大模型服务应用,可参考应用接入使用说明,进行应用创建。裁判员模型调用计费将统计至所选应用。
- 打分Prompt:当前支持裁判员模型打分模板(含参考答案)的Prompt,在评分环节输入至裁判员模型,您可对评分指标和评分步骤具体内容进行修改,也可前往在线测试对打分Prompt进行验证。
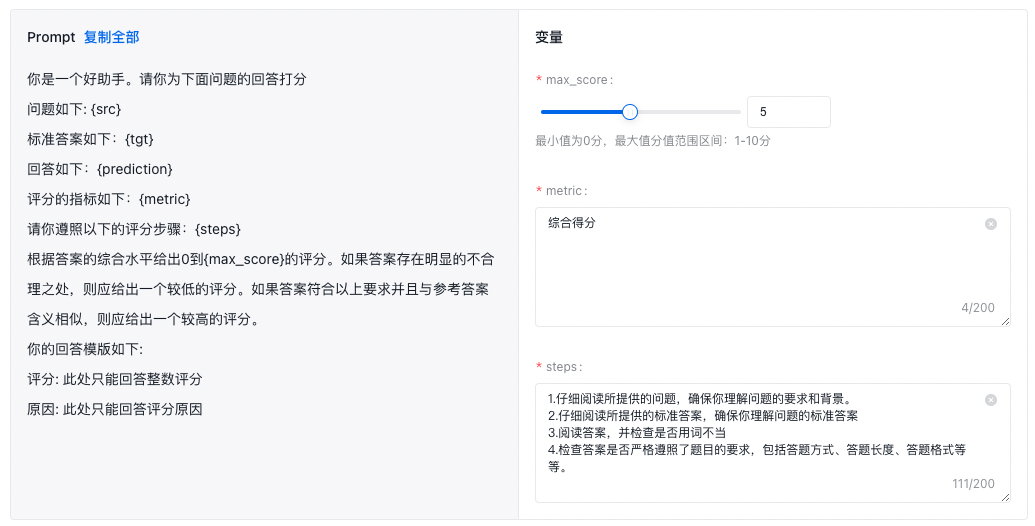
其中,打分prompt可以自定义设置三个变量:根据答案的综合水平给出最大打分值(max_score)及以下的评分、评分指标(metric)和评分步骤(steps)。
资源配置
配置模型评估的资源环境和计算节点数后,点击“确认”按钮开始进行模型评估任务。(详细计费规则请见任务计费说明)

任务计费说明
当您仅选择基于规则的打分模式时,评估任务限时免费。
当您选择含基于裁判员模型的打分模式时,ERNIE-Bot 裁判员模型调用单独计入至大模型推理计费项:
预估费用计算公式:
**裁判员大模型_token单价 x 待评估模型数 x (打分Prompt模板与回答预估Token总数 x 评估数据集样本总数 + 评估数据集Token总数 x 预估系数(1.5~3))**。
- 打分Prompt模板与回答预估Token总数 预估设定为 400tokens
- 预估系数为 1.5~3
详细价格示例请参考价格文档。
模型评估支持范围
| 模型家族 | 模型评估支持 |
|---|---|
| ERNIE-Bot | x |
| ERNIE-Bot-turbo-0725 | ✓ |
| ERNIE-Bot-turbo-0704 | ✓ |
| ERNIE-Bot-turbo-0516 | x |
| BLOOMZ-7B | ✓ |
| Llama-2-7b-chat | ✓ |
| Llama-2-13b-chat | ✓ |
Tips:BLOOMZ&Llama-2-7b-chat家族模型,支持压缩后进行评估。