查看与管理模型评估任务
查看模型评估任务详情
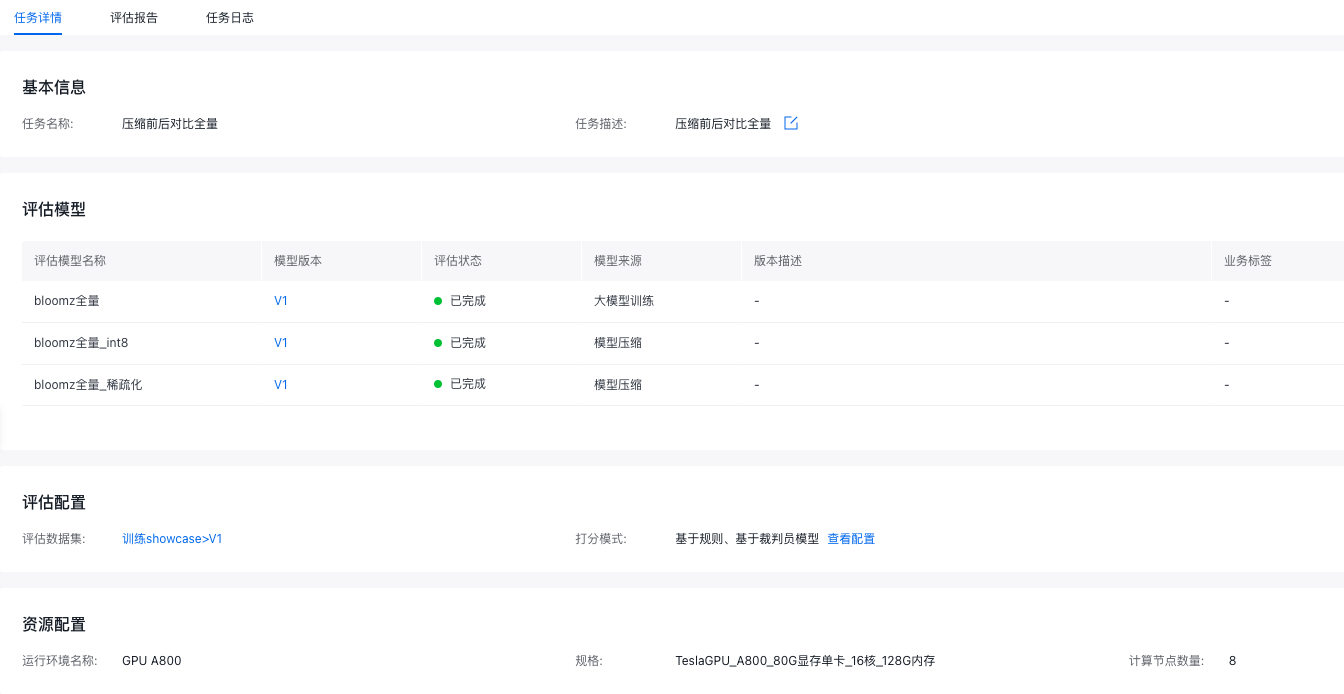
查看评估报告
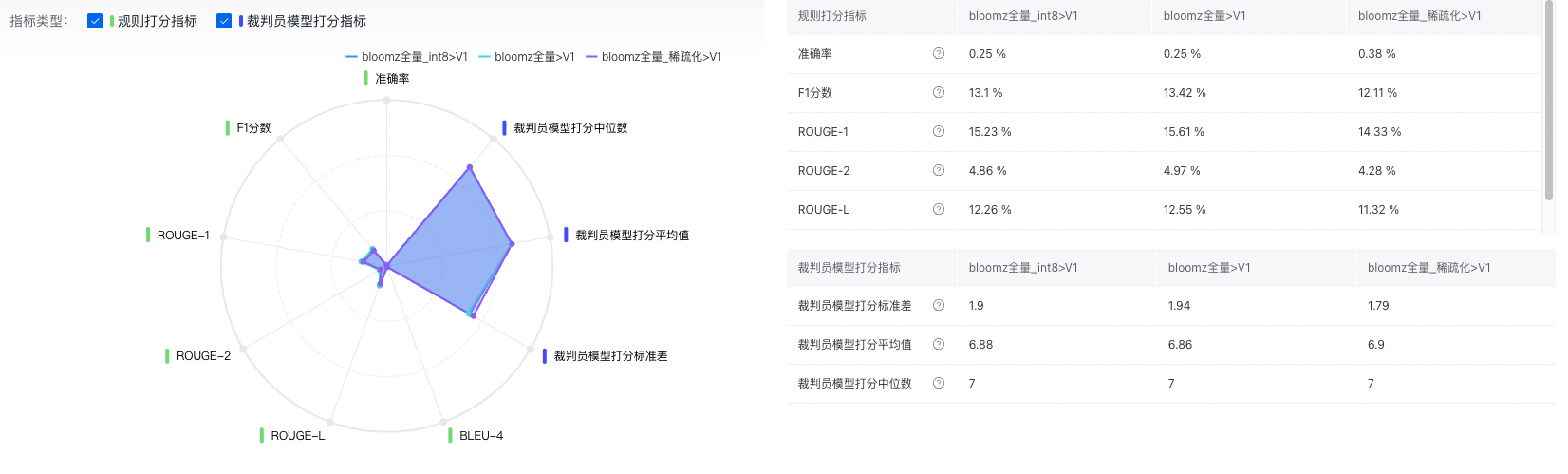
规则打分指标
| 指标名称 | 指标说明 |
|---|---|
| 准确率 (%) | 规则打分模式下,忽略停用词后,正确预测(标注与预测完全匹配)的样本数与总样本数的比例 |
| F1分数 (%) | 规则打分模式下,忽略停用词后,精确率和召回率的调和平均数 |
| ROUGE-1 (%) | 忽略停用词后,将模型生成的结果和标准结果按unigram拆分后,计算出的召回率 |
| ROUGE-2 (%) | 忽略停用词后,将模型生成的结果和标准结果按bigram拆分后,计算出的召回率 |
| ROUGE-L (%) | 忽略停用词后,衡量了模型生成的结果和标准结果的最长公共子序列,并计算出召回率 |
| BLEU-4 (%) | 忽略停用词后,用于评估模型生成的句子和实际句子的差异的指标,值为unigram,bigram,trigram,4-grams的加权平均 |
Ⅰ) unigram:指将句子或文本中的每个单词都单独作为一个基本单元,不考虑单词之间的顺序。
Ⅱ) bigram:指将句子或文本中的每个相邻的单词对都作为一个基本单元,用于描述两个单词之间的顺序关系。
Ⅲ) trigram:指将句子或文本中的每个相邻的三个单词作为一个基本单元,用于描述三个单词之间的顺序关系。
Ⅳ) 4-grams:指将句子或文本中的每个相邻的四个单词作为一个基本单元,用于描述四个单词之间的顺序关系。
Ⅴ) 最长公共子序列:指两个或多个字符串最长的子序列,这些子序列在每个字符串中都存在,且它们的顺序相同。
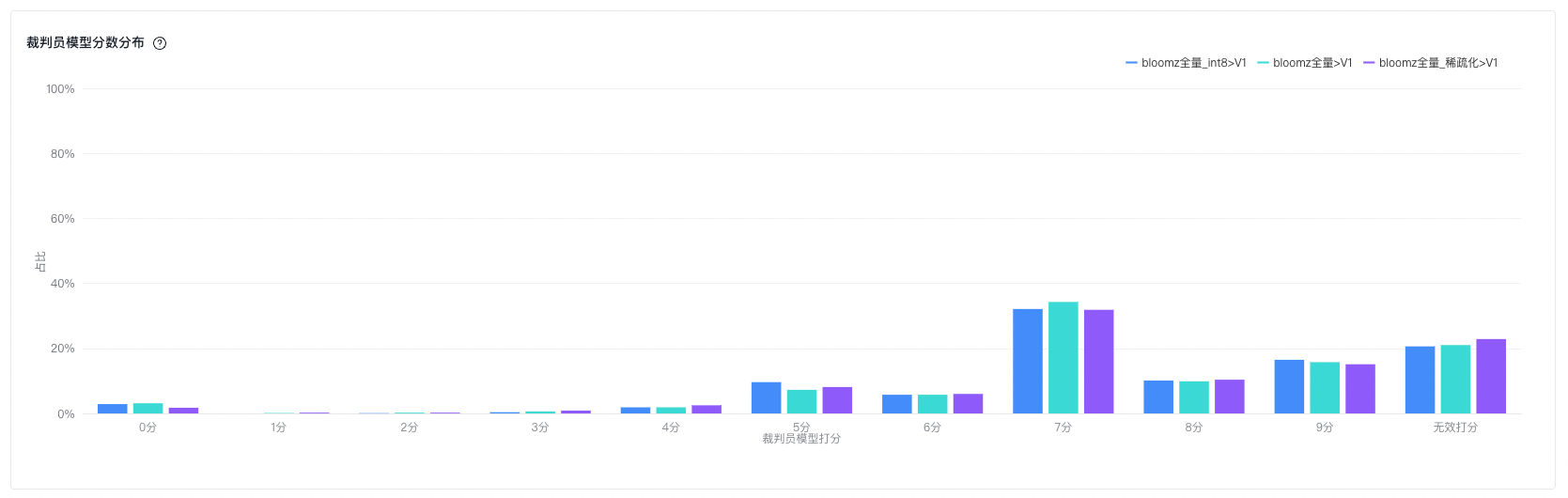
裁判员模型打分指标
| 指标名称 | 指标说明 |
|---|---|
| 裁判员模型打分标准差 | 裁判员大模型对模型生成结果打分的标准差(不含无效打分) |
| 裁判员模型打分平均值 | 裁判员大模型对模型生成结果打分的平均值(不含无效打分) |
| 裁判员模型打分中位数 | 裁判员大模型对模型生成结果打分的中位数(不含无效打分) |
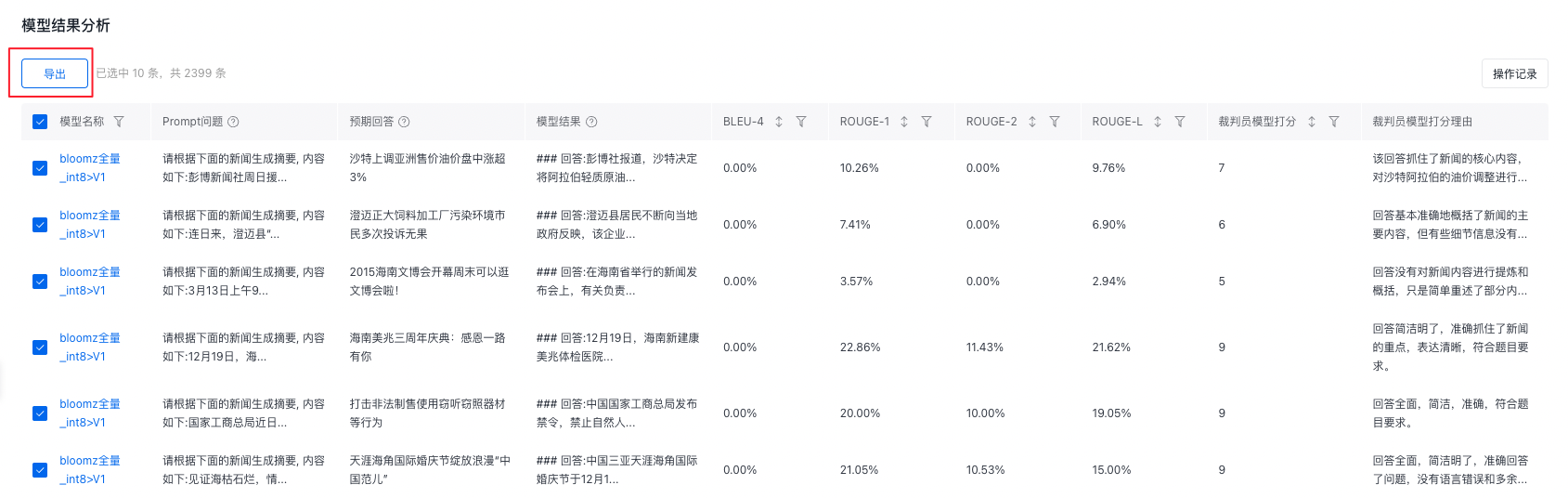
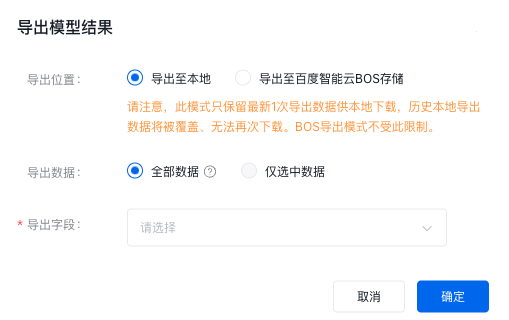
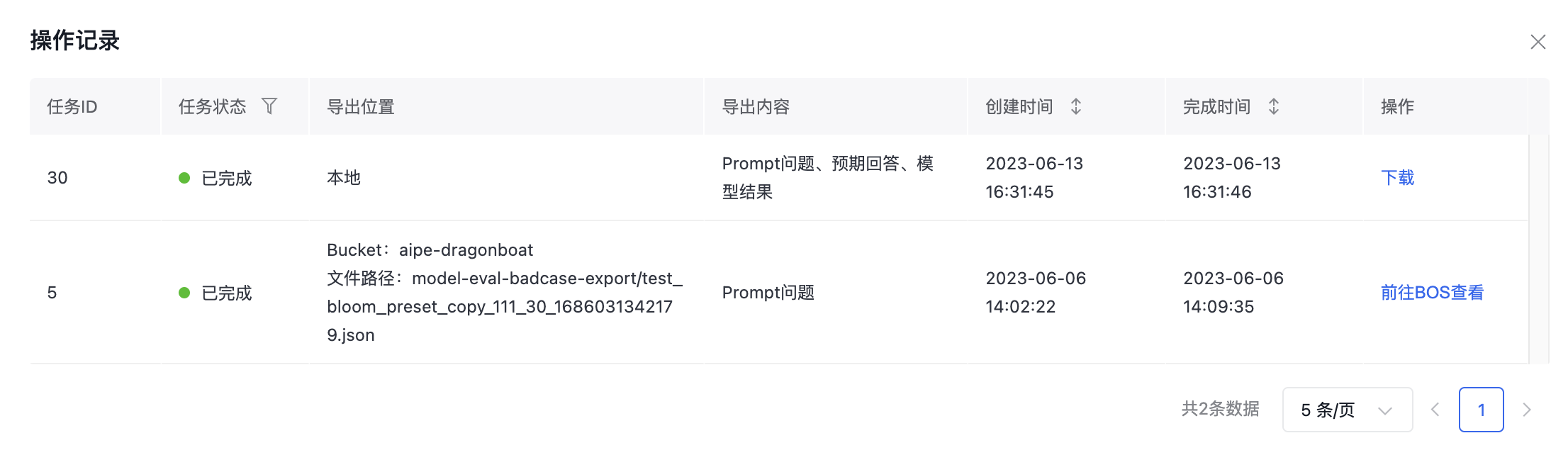
导出模型结果分析
查看任务日志
