创建 SFT 任务
SFT实际上是Fine-Tuning的训练模式,开发者可以选择适合自己任务场景的训练模式并加以调参训练,从而实现理想的模型效果。
登录到千帆大模型操作台,在左侧功能列选择SFT,进入SFT主任务界面。
创建任务
您需要在SFT任务界面,选择“创建训练任务”按钮。
填写好任务名称后,在范围内选择所属行业和应用场景,再进行500字内的业务描述即可。

当您选择“创建并训练”则直接开启训练模型的运行配置界面;“完成创建”仅创建任务不创建训练模型的运行。
当前支持SFT任务具备大语言模型和文生图大模型两种任务类型。
大语言模型
新建运行
您可以在创建任务时选择“创建并训练”,或者在SFT任务列表中,选择指定任务的“新建运行”按钮。
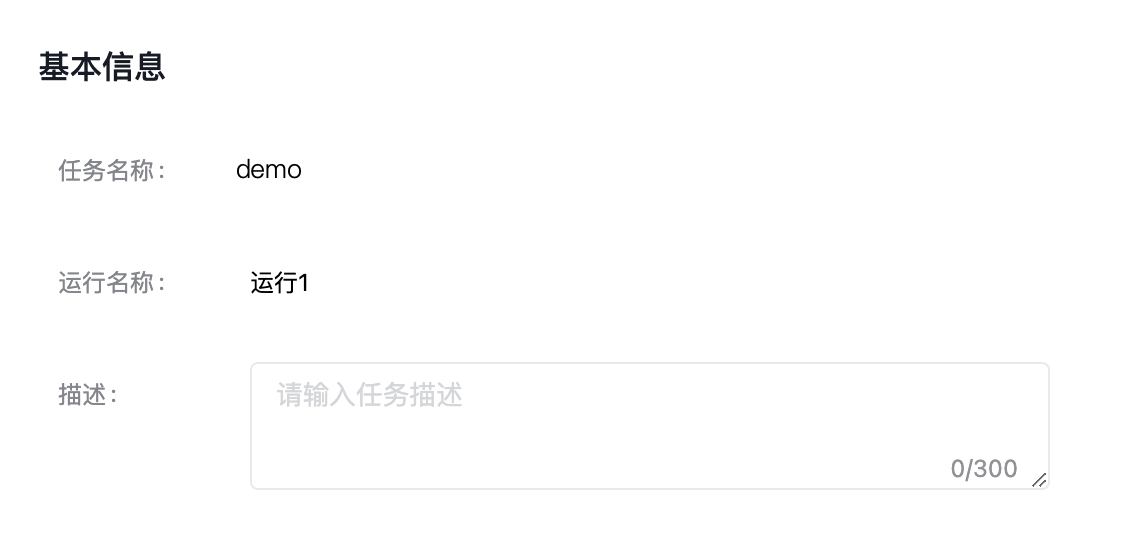
进入模型训练的任务运行配置页,填写基本信息。
训练配置
训练配置大模型参数,调整好基本配置。
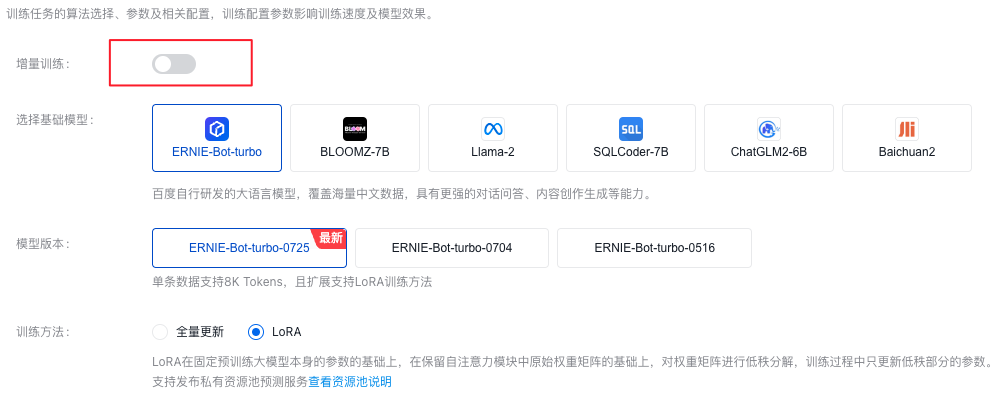
- 在SFT训练任务中,可以选择开启增量训练开关。需注意的是,基准模型为“全量更新”训练出来的模型,才支持开启此开关。
开关打开后,需要选择SFT的基准模型,此模型来源于运行中的SFT任务。所以您开启增量训练任务的前提有已经在运行中的SFT任务。

注意:基础模型继承基准模型(全量更新所得)版本,所以当您选定基准模型后,基础模型及版本不可变更。
- 您也可以选择直接不使用增量训练,这样直接在基础模型上进行SFT。

·ERNIE-Bot-turbo
百度自行研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力。
ERNIE-Bot-turbo-0725
单条数据支持8k Tokens,且扩展支持LoRA训练方法。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| LoRA | LoRA在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 单条数据的长度,单位为token。如果数据集中每条数据的长度(输入)都在4096 tokens 以内,建议选择4096,针对短序列可以达到更优的训练效果。 |
ERNIE-Bot-turbo-0704
修复输出不稳定等问题。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| Prompt Tuning | Prompt Tuning在固定预训练大模型本身的参数的基础上,增加prompt embedding参数,并且训练过程中只更新prompt参数。 |
| LoRA | LoRA在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
如您选择的训练方法为Prompt Tuning,则支持模型发布在线服务到公共资源池。
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
ERNIE-Bot-turbo-0516
ERNIE-Bot-turbo经典版本
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(BatchSize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
·BLOOMZ-7B
知名的大语言模型,由HuggingFace研发并开源,能够以46种语言和13种编程语言输出文本。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| Prompt Tuning | 在固定预训练大模型本身的参数的基础上,增加prompt embedding参数,并且训练过程中只更新prompt参数。 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
Llama-2
Llama 是Facebook 推出的开源大语言模型。千帆团队在开源模型基础上做了中文增强。
Llama-2-7b
Qianfan-Chinese-Llama-2-7b,千帆团队在Llama-2-7b基础上的中文增强版本。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| Prompt Tuning | 在固定预训练大模型本身的参数的基础上,增加prompt embedding参数,并且训练过程中只更新prompt参数。 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
Llama-2-13b
Qianfan-Chinese-Llama-2-13b,千帆团队在Llama-2-13b基础上的中文增强版本。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| Prompt Tuning | 在固定预训练大模型本身的参数的基础上,增加prompt embedding参数,并且训练过程中只更新prompt参数。 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
·SQLCoder-7B
由Defog研发、基于Mistral-7B微调的语言模型,用于将自然语言问题转换为SQL语句,具备优秀的生成效果。使用Apache 2.0、CC-BY-SA-4.0协议。根据CC-BY-SA-4.0协议要求,您需要将修改后的模型权重在CC-BY-SA-4.0license中开源。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
·ChatGLM2-6B
智谱AI与清华KEG实验室发布的中英双语对话模型,具备强大的推理性能、效果、较低的部署门槛及更长的上下文,在MMLU、CEval等数据集上相比初代有大幅的性能提升。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
·Baichuan2-13B-Chat
单条数据支持4096 tokens。Baichuan2-13B-Chat 是百川智能推出的新一代开源大语言模型,采用2.6万亿Tokens的高质量语料训练。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
数据配置
训练任务的选择数据及相关配置,大模型调优任务需要匹配多轮对话-非排序类的数据集。
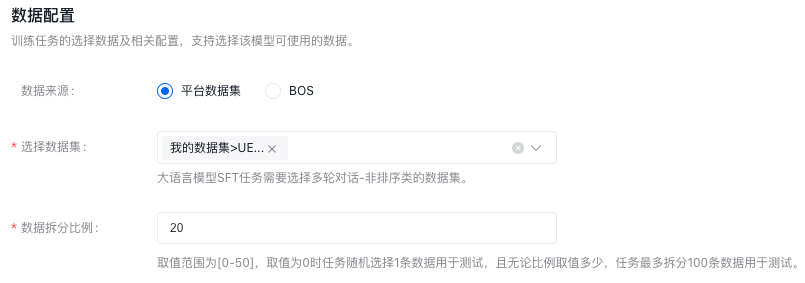
数据集来源可以为千帆平台已发布的数据集版本或者预置数据集,也可以为已有数据集的BOS地址,详细内容可查看数据集部分内容。
数据拆分比例:比如设置20,则表示选定数据集版本总数的80%作为训练集,20%作为验证集。
若数据集保存在BOS中,请勿在提交任务后修改BOS数据。修改后可能会导致任务失败!
需注意:当选择BOS目录导入数据集时,数据放在jsonl文件夹下。您需要选择jsonl的父目录:
- 奖励模型支持单轮对话、多轮对话有排序数据。
- RLHF训练支持仅prompt数据。
- SFT支持单轮对话,多轮对话需要有标注数据。
- BOS目录导入数据要严格遵守其格式要求,如不符合此格式要求,训练作业无法成功开启。详情参考BOS导入无标注信息格式和BOS导入有标注信息格式。
以上所有操作完成后,点击“开始训练”,则发起模型训练的任务。
文生图大模型
新建运行
您可以在创建任务时选择“创建并训练”,或者在SFT任务列表中,选择指定任务的“新建运行”按钮。
进入模型训练的任务运行配置页,填写基本信息。
训练配置
训练配置大模型参数,调整好基本配置。

- 在SFT训练任务中,可以选择开启增量训练开关。
开关打开后,需要选择SFT的基准模型,此模型来源于运行中的SFT任务。所以您开启增量训练任务的前提有已经在运行中的SFT任务。
注意:基础模型继承基准模型(全量更新所得)版本,所以当您选定基准模型后,基础模型及版本不可变更。
- 您也可以选择直接不使用增量训练,这样直接在基础模型上进行SFT。

·Stable_diffusion XL 1.0
业内知名的跨模态大模型,由StabilityAI研发并开源,有着业内领先的图像生成能力。
| 训练方法 | 简单描述 |
|---|---|
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
数据配置
训练任务的选择数据及相关配置,支持选择该模型可使用的数据。
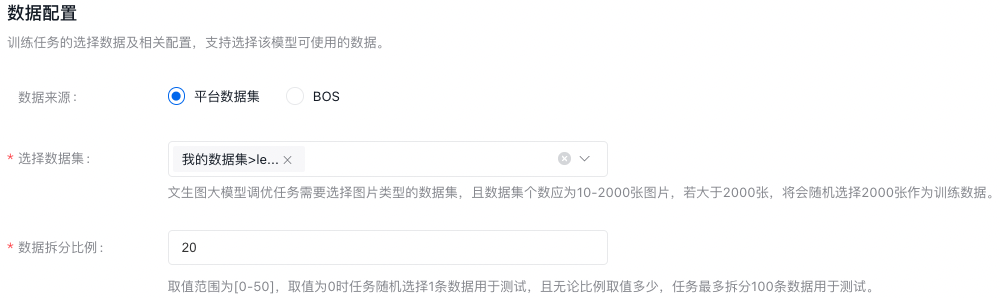
文生图大模型调优任务需要选择图片类型的数据集,且数据集个数应为10-2000张图片,若大于2000张,将会随机选择2000张作为训练数据。
数据集来源可以为千帆平台已发布的数据集版本,也可以为已有数据集的BOS地址,详细内容可查看数据集部分内容。
数据拆分比例:比如设置20,则表示选定数据集版本总数的80%作为训练集,20%作为验证集。
若数据集保存在BOS中,请勿在提交任务后修改BOS数据。修改后可能会导致任务失败!
需注意:当选择BOS目录导入数据集时,数据放在jsonl文件夹下。
百度BOS服务开通申请。
资源配置
文生图大模型支持将训练加入GPU,当前默认规格如下:

以上所有内容完成后,即可发起模型训练任务。
关于训练费用可查看价格文档。大模型训练模块会根据数据集大小,预估训练时长,其中最小计量粒度为0.01小时,不足0.01小时按0.01小时计算。