创建 Post-pretrain 任务
在Post-pretrain任务中调优预训练模型提升模型效果,完成预训练后,可以在SFT调优预训练模型。
创建任务
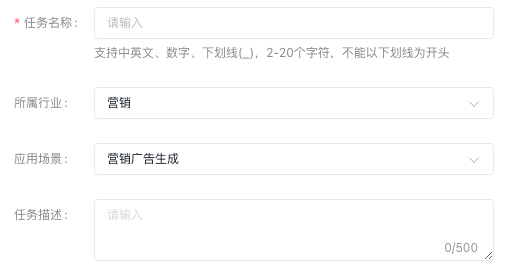
新建运行
进入模型训练的任务运行配置页,填写基本信息。
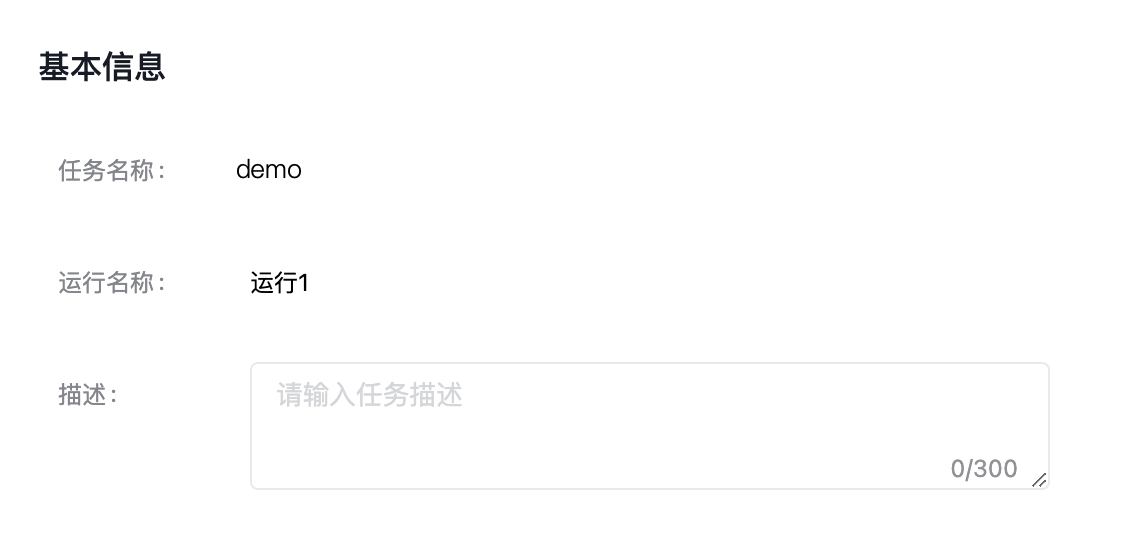
训练配置

开关打开后,需要选择Post-pretrain的基准模型,此模型来源于运行中的Post-pretrain任务。所以您开启增量训练任务的前提有已经在运行中的Post-pretrain任务。


·Llama-2
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较�大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 正则化系数 | 正则化系数(Weight_decay),用于防止模型对训练数据过拟合。但系数过大,可能导致欠拟合。 |
数据配置
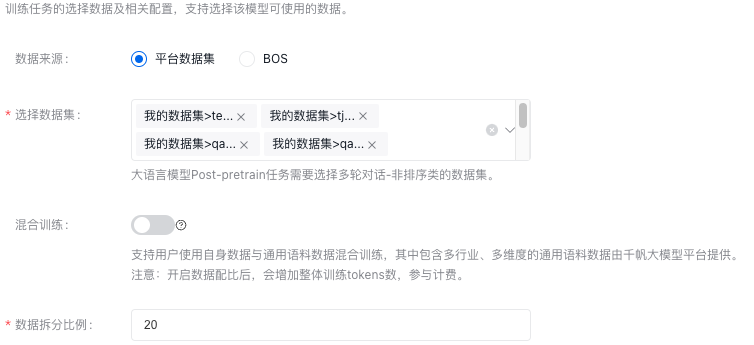
需注意:任务运行推荐数据量至少10亿tokens,如您试用的话,则推荐1千万tokens及以上的数据量。
混合训练:支持用户使用自身数据与通用语料数据混合训练,其中包含多行业、多维度的通用语料数据由千帆大模型平台提供。
注意:开启数据配比后,会增加整体训练tokens数,参与计费。

修改于 2026-06-17 03:44:15