创建模型评估任务
什么是评估数据集
创建模型评估任务
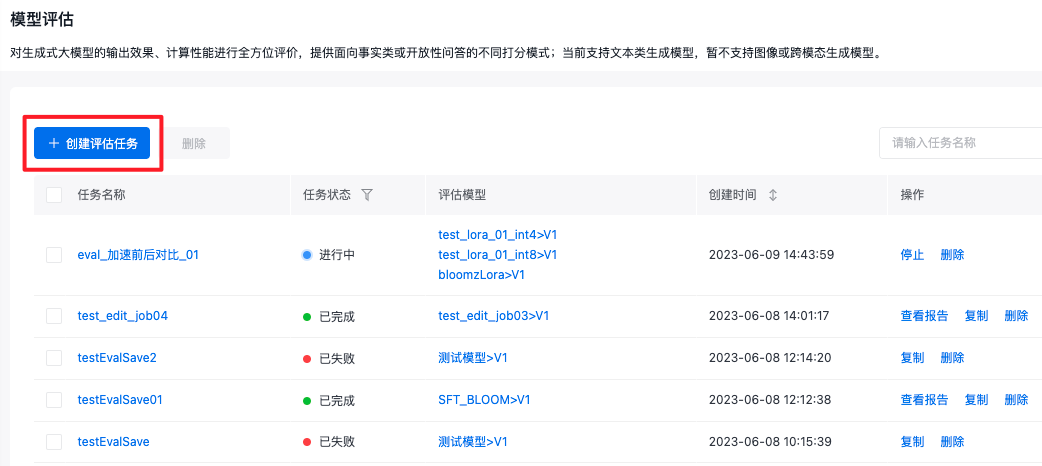
基本信息
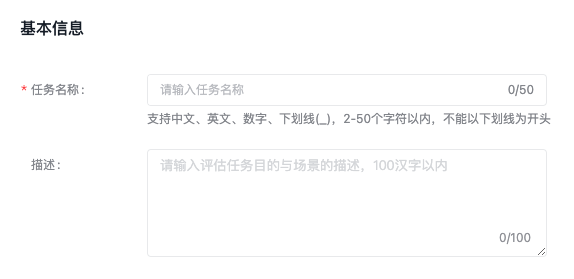
评估配置
基于规则
为避免特殊字符及单词对模型效果评估的影响,可设置停用词表,评估时将自动过滤。下载停用词表示例(以空格或回车分隔不同停用词)。
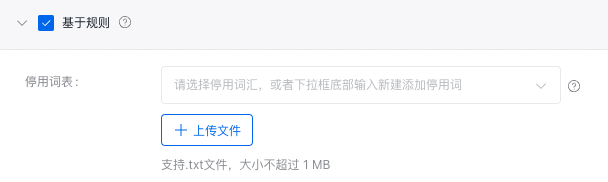
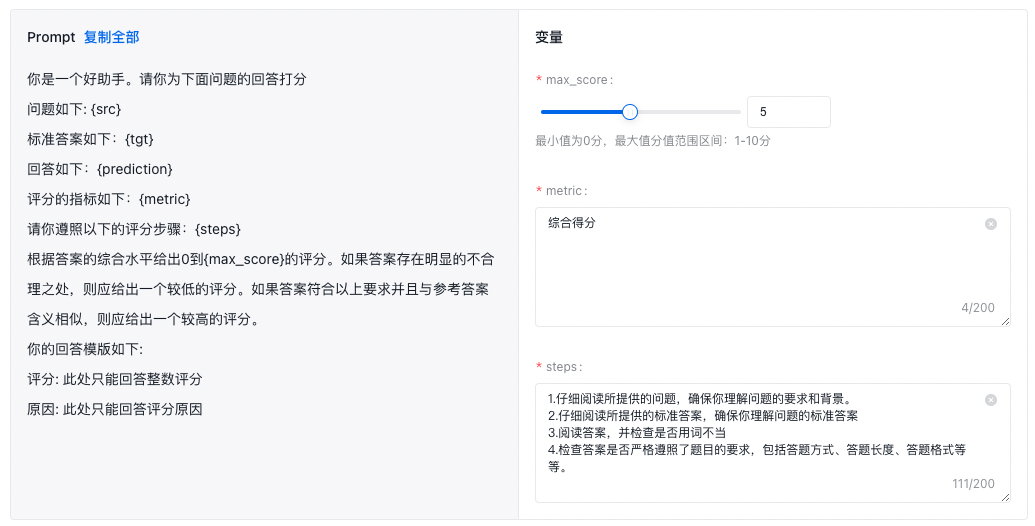
基于裁判员模型
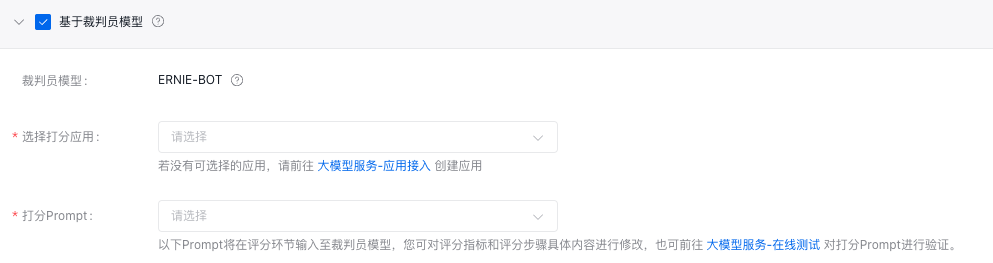
资源配置

任务计费说明
预估费用计算公式:
裁判员大模型_token单价 x 待评估模型数 x (打分Prompt模板与回答预估Token总数 x 评估数据集样本总数 + 评估数据集Token总数 x 预估系数(1.5~3))。
模型评估支持范围
| 模型家族 | 模型评估支持 |
|---|---|
| ERNIE-Bot | x |
| ERNIE-Bot-turbo-0725 | ✓ |
| ERNIE-Bot-turbo-0704 | ✓ |
| ERNIE-Bot-turbo-0516 | x |
| BLOOMZ-7B | ✓ |
| Llama-2-7b-chat | ✓ |
| Llama-2-13b-chat | ✓ |
修改于 2026-06-17 03:44:15