知识库管理
创建知识库
基本信息
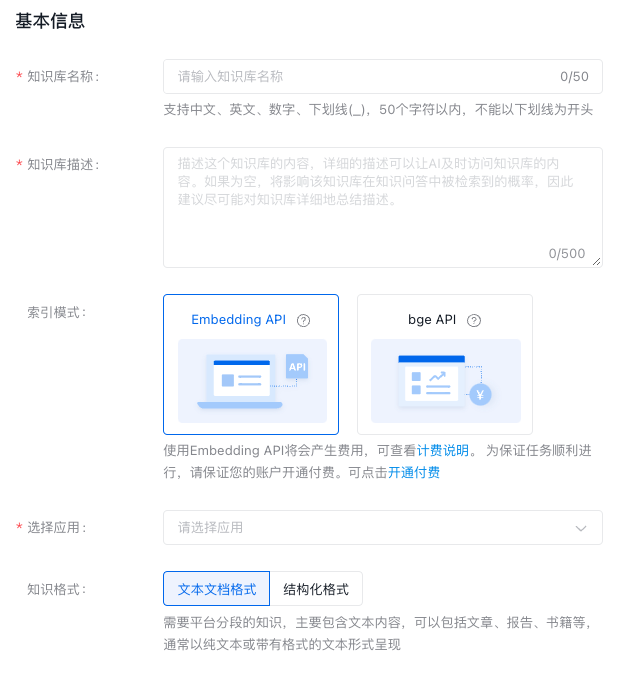
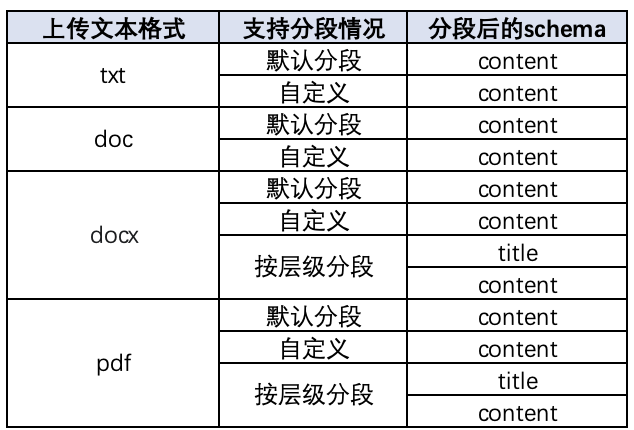
文本文档格式

1.
2.
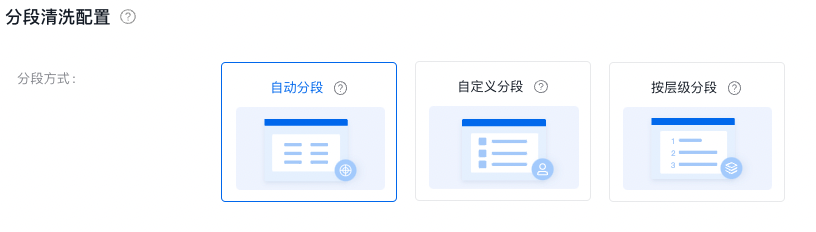
分段清洗配置
自动分段
自定义
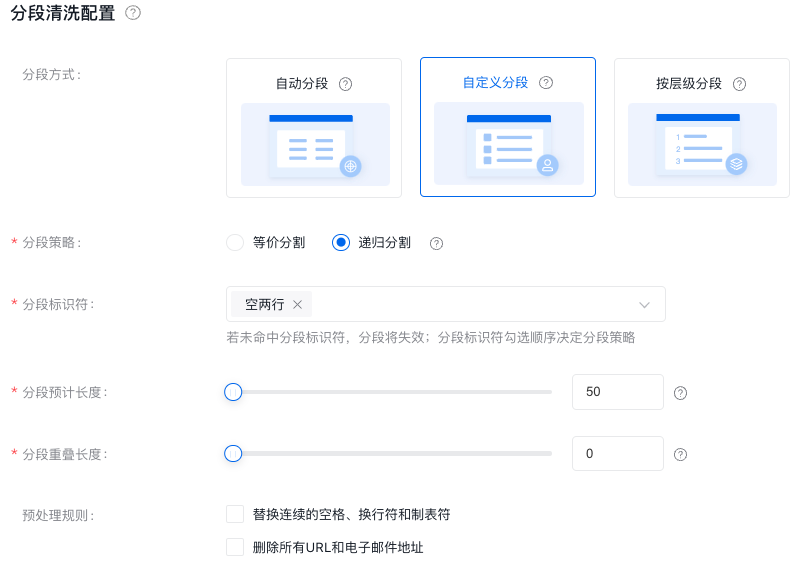
递归分割:按照所选符号先后顺序做递归分割,同一优先级的分割结果合并到预计长度。
如图所示,分段策略选了递归分割,分段标识符将按照勾选顺序运行分段策略:
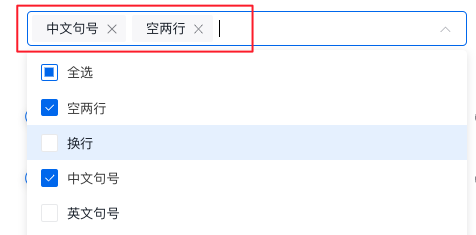

按层级分段

递归分割:按照所选符号先后顺序做递归分割,同一优先级的分割结果合并到预计长度。
如图所示,分段策略选了递归分割,分段标识符将按照勾选顺序运行分段策略:
分段清洗提示说明
1.
在处理文本数据时,分段和清洗是两个重要的预处理步骤。通过对数据集进行适当的分段和清洗,可以提高模型在实际应用中的表现,从而为用户提供更准确、更有价值的结果。
2.
分段的目的是将长文本拆成小段落、以便模型更有效的处理和理解。这有助于提高模型生成结果的质量和相关性。
3.
清洗是对文本进行预处理,删除不必要的字符、符号或格��式,使数据集更加干净和整洁,便于模型解析。
索引配置
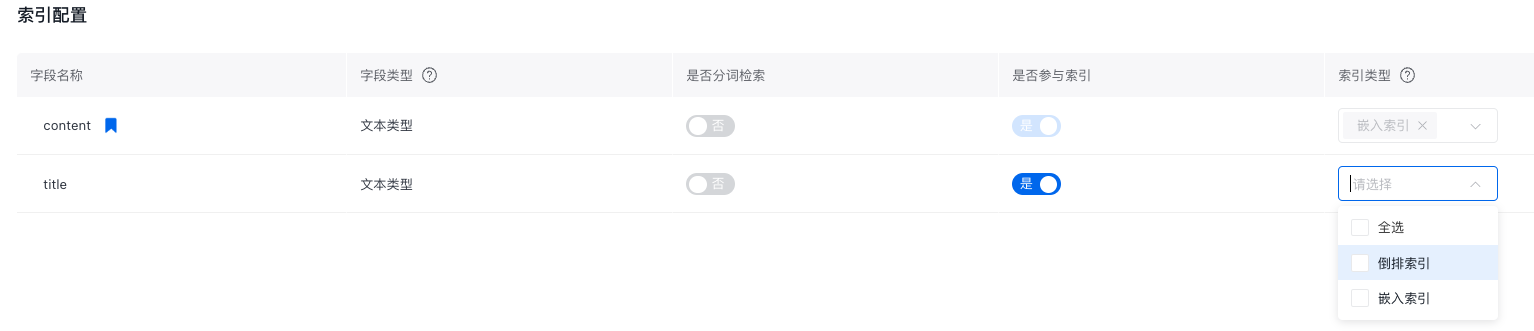
倒排索引用于关键字过滤,嵌入索引用于语义检索。
结构化格式
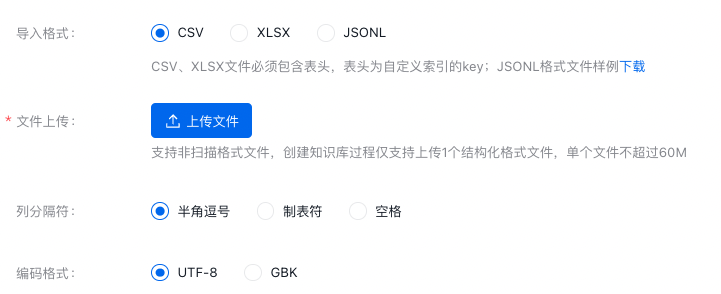
1.
2.
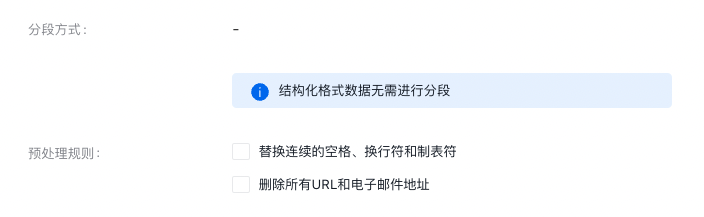
分段清洗配置
索引配置

操作知识库

详情
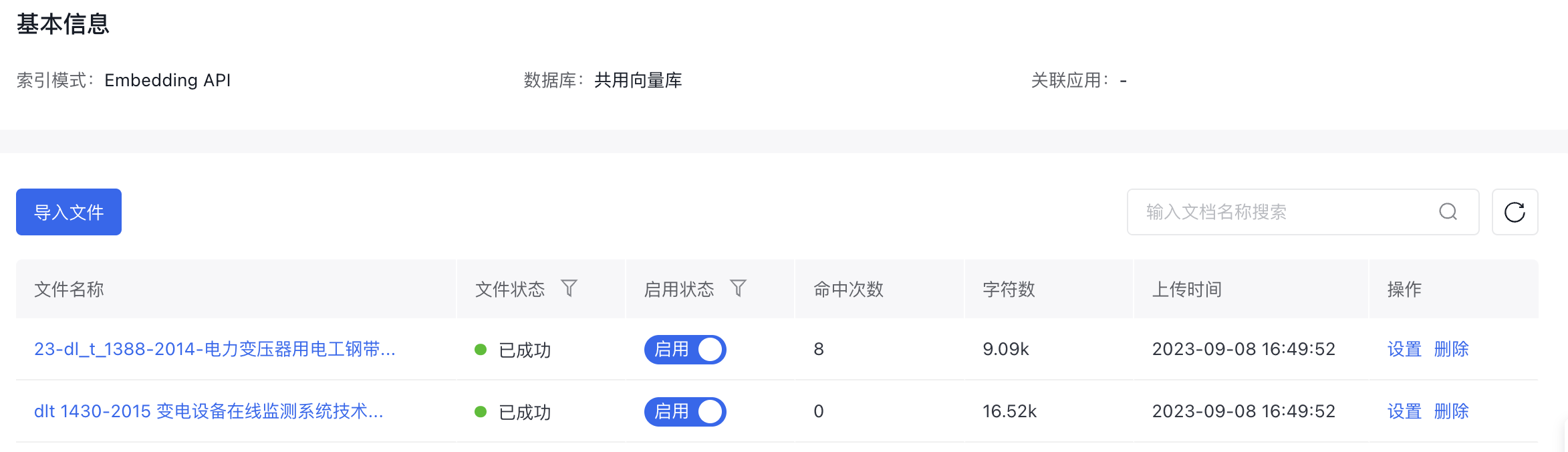
导入文件
文件信息概览
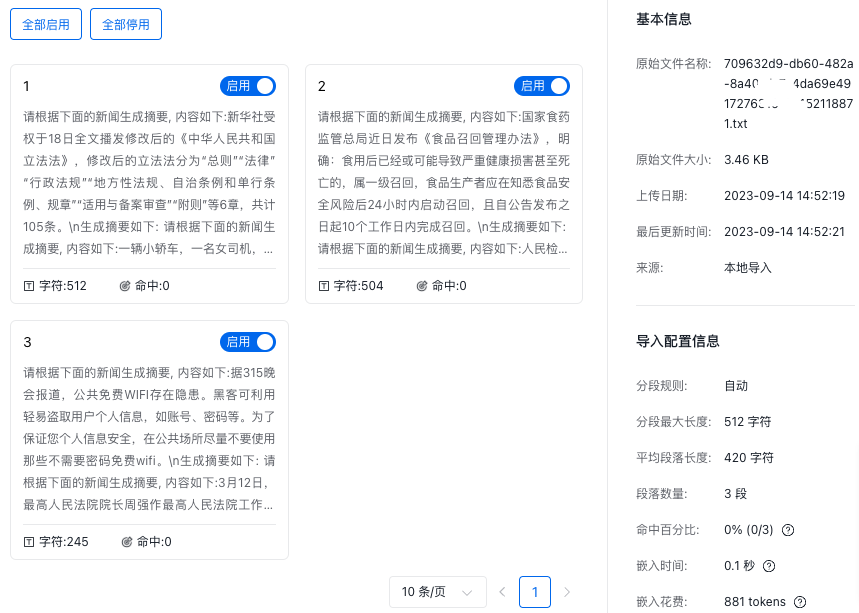
命中百分比:搜索被命中的片段占总片段数的百分比;
嵌入时间:文档向量化所用耗时;
嵌入花费:文档向量化消耗的tokens数。
索引配置详情
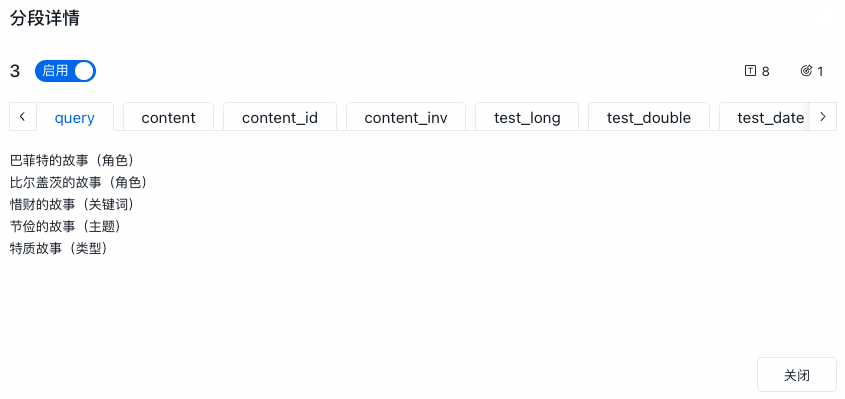
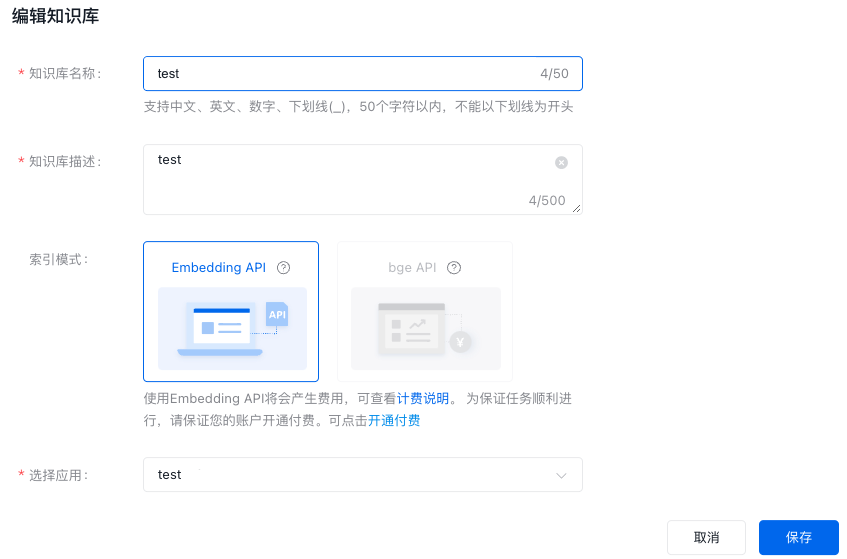
编辑
删除
引用知识库
修改于 2026-06-17 03:44:15